How Hash Tables Actually Work
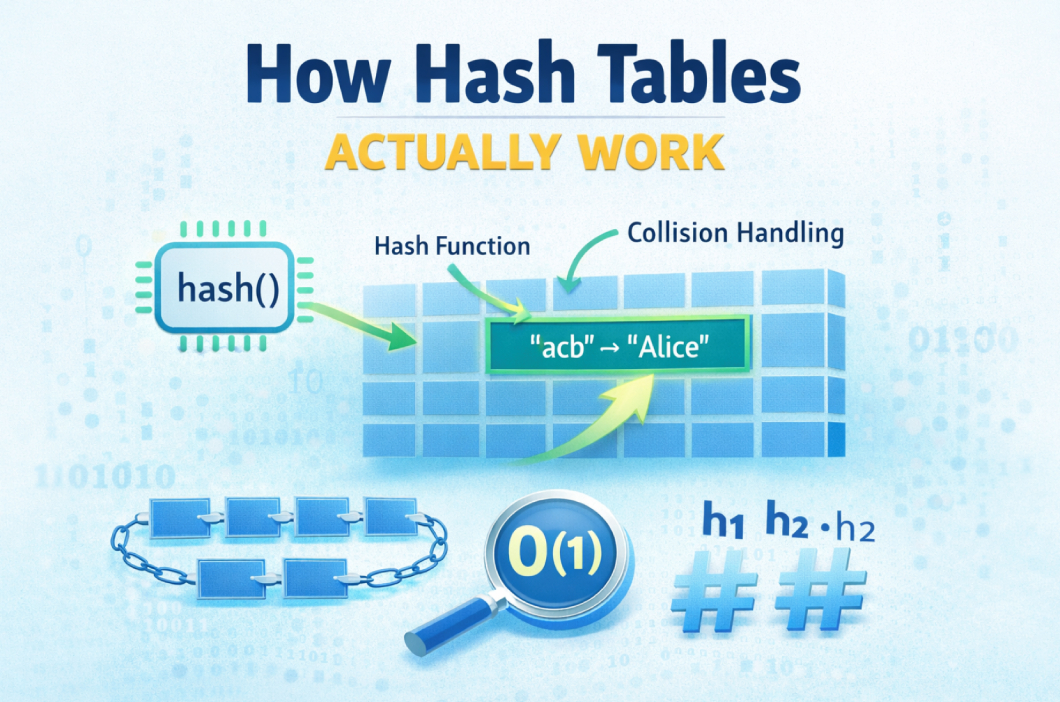
Ở bài trước, chúng ta đã thấy vì sao Fast Lookup là vấn đề sống còn của backend systems và Hash Table chính là nền tảng phía sau lời giải đó.
-> Nhưng nói “Hash Table giúp lookup O(1)” mới chỉ là phần nổi, vậy cơ chế nào, hay cách hoạt động ra sao?
-> Vì sao chỉ một cấu trúc dựa trên mảng lại có thể giúp hệ thống xử lý hàng triệu request mỗi giây?
-> Điều gì thật sự xảy ra bên trong một Hash Table?
1. Hash Function — Cốt lõi của Hash Table
Hash function nhận đầu vào là một key (string, object,…) và biến (hash) nó thành một số nguyên. Con số này sau đó được dùng để xác định vị trí lưu dữ liệu trong bộ nhớ.
index = hash(key) % table_size
Hash function tốt cần đáp ứng tiêu chí:
- Tính toán index phải cực nhanh
- Phân bố key đồng đều
- Hạn chế tối đa trùng index
Hash Table thực chất chỉ là một mảng lớn trong RAM, và nhờ hash function, việc truy cập dữ liệu không còn phụ thuộc vào kích thước dataset.
Ví dụ:
Dataset:
user:1001 -> Alice user:1002 -> Bob user:1003 -> Charlie
Hash function:
hash(key) = sum(ascii(key)) % table_size
Table lưu có dạng:
index | key | value 0 | user:1001 | Alice 1 | user:1002 | Bob 2 | user:1003 | Charlie
Hash function dùng để biến key bất kỳ thành một số nguyên (integer) -> sau đó map vào index của table. Hash Table thực chất chỉ là một mảng (array).
2. Insert & Lookup hoạt động thế nào?
Cơ chế hoạt động của Hash Table như sau:
INSERT: Khi một dữ liệu mới được thêm vào hash table:
function put(key, value):
index = hash(key)
table[index] = (key, value)
LOOKUP: Lấy dữ liệu ra
function get(key):
index = hash(key)
return table[index]
Về mặt lý thuyết độ phức tạp là: O(1).
Thực tế không đơn giản vậy, đời không đẹp vậy đâu, sẽ có trường hợp gọi là: Hash Collision.
Về lý thuyết thì là O(1), nhưng thực tế hai Key khác nhau hoàn toàn nhưng qua Hash function lại cho ra cùng một index.
Ví dụ: Hash("abc") và Hash("acb") đều ra 5.
Khi đó, một Hash Function tốt cần đạt được 3 tiêu chí về tốc độ, phân bố và tránh trùng index có nêu ở trên:
3. Vấn đề Hash Collision
Hai key khác nhau nhưng bị đẩy vào cùng một vị trí (index) trong hash table, là vấn đề collision xảy ra:
hash(key1) == hash(key2)
Vậy, để đảm bảo tất cả dữ liệu đều được lưu trong hash table, và tốc độ truy xuất phải nhanh nhất. Có hai hướng giải quyết phổ biến để xử lý xung đột (collision) là: Chaining, Open Addressing.
3.1. Chaining - sử dụng Bucket
Thay vì lưu một giá trị duy nhất, mỗi index trong table sẽ chứa một Bucket (thường là Linked List hoặc Dynamic Array).
- Ưu điểm: Dễ triển khai, không sợ đầy table.
- Nhược điểm: Nếu Bucket quá dài, lookup sẽ từ O(1) "thoái hóa" thành O(n).
- Khắc phục: Các hệ thống sẽ tự động Resize table để giữ các Bucket này luôn ngắn nhất có thể.
Ví dụ:
index | bucket
0 | []
1 | [("abc","Bob"), ("acb","Alice")]
2 | [("xyz","David")]
3 | []
PUT: Nếu hash trùng index:
bucket.append(key,value)
GET: 3 bước:
Bước 1. Hash key:
index = hash("acb") % 4 = 1
Bước 2. Lấy hết bucket:
bucket = table[1]
Bước 3. Duyệt bucket, để so sánh khớp key:
("abc","Bob") → key không match
("acb","Alice") → key match
Return: Alice
=> Độ phức tạp sẽ: Tốt nhất là O(1), và Xấu nhất là O(n).
Điểm quan trọng: Thoạt nhìn có vẻ Chaining không cần resize table, vì bucket có thể lớn vô hạn.
Nhưng nếu bucket quá lớn: lookup -> scan hết bucket -> Khi đó độ phức tạp lại trở thành: O(n)
Vì vậy hệ thống production thường sẽ resize table tại thời điểm nào đó để giữ bucket nhỏ, và đảm bảo lookup gần O(1). [đọc ở phần bên dưới để hiểu khi nào resize table].
3.2 Open Addressing - Tìm vị trí còn trống
Tinh thần, mọi dữ liệu nằm trực tiếp trong table. Nếu chỗ đó bị chiếm rồi, ta đi tìm chỗ khác.
- Linear Probing: Cứ thế nhảy xuống slot tiếp theo: index + 1.
- Quadratic Probing: Nhảy theo bình phương (1^2,2^2,3^2) để phân tán dữ liệu tốt hơn.
- Double Hashing: Dùng thêm một hàm Hash thứ hai để tính bước nhảy. Đây là kỹ thuật giúp dữ liệu phân bố cực đều.
Linear Probing:
Ý tưởng: Nếu index bị chiếm → kiểm tra index tiếp theo.
Ví dụ: Table hiện tại:
index | key | value
0
1
2 abc Bob
3 acb Alice
4
=================================
INSERT:
put("bca","Charlie")
Hash:
hash("bca") % 5 = 2
Kiểm tra:
2 → full
3 → full
4 → empty
→ đặt tại: index = 4
=================================
Table mới sẽ là:
index | key | value
0
1
2 abc Bob
3 acb Alice
4 bca Charlie
=================================
LOOKUP:
get("bca")
Hash:
hash("bca") % 5 = 2
Kiểm tra tuần tự:
2 → abc ≠ bca
3 → acb ≠ bca
4 → bca → FOUND
Tìm thấy thì trả về: 'Charlie'
Linear probing có một vấn đề gọi là: Primary Clustering.
Khi nhiều phần tử liên tiếp bị chiếm: [slot][slot][slot][slot][empty], khi đó Lookup sẽ phải scan qua rất nhiều slot mới tìm được vị trí thích hợp để đặt.
Quadratic Probing
Tương tự vẫn tìm vị trí đặt, nhưng thay vì: index + 1, Quadratic probing sẽ nhảy theo bước:
index + 1² index + 2² index + 3² Ví dụ: hash = 2 thử: 2 2+1² = 3 2+2² = 6 2+3² = 11
Giúp giảm clustering so với Linear.
Double Hashing
Sử dụng hash function thứ hai.
index = (hash1(key) + i * hash2(key)) % table_size
Ưu điểm: Phân bố đều hơn, giảm clustering
Đây là kỹ thuật được dùng trong nhiều production hash tables.
4. Khởi tạo table size và resize table theo nguyên tắc nào?
Một hash table tốt phải quản lý:
- table size
- load factor
- resize strategy
Khi sử dụng Hash Table, cần biết khi nào nó "nghẽn" hay "nổ". Đó là lúc phải quan tâm tới Load Factor.
α = number_of_elements / table_size
Ngưỡng tốt nhất: α: 0.5 – 0.75
Khi vượt ngưỡng: load_factor > threshold → resize table.
Độ phức tạp của hành động resize là: O(n)
Nhưng resize không xảy ra thường xuyên, nên độ phức tạp vẫn gần về: O(1).
Lựa chọn Table size ban đầu cũng theo chỉ số Load Factor này.
Hash Tables trong các hệ thống lớn sẽ được lưu trữ trên RAM để tăng tốc (Redis); và Distributed caches (Cassandra/Memcached) - khi một node không đủ, người ta dùng Consistent Hashing để phân tán Key ra hàng trăm node khác nhau mà vẫn đảm bảo Lookup cực nhanh.
5. Trade-offs ở đây là gì?
Hash table không phải lúc nào cũng hoàn hảo, các vấn đề chính: Collision; Hash function kém → collision nhiều; Resize cost, Resize cần: O(n) để rehash toàn bộ dữ liệu.
Memory overhead: Để tránh collision, hash table phải allocate nhiều memory hơn dữ liệu thực.
Vì vậy trong production systems thường:
- pre-allocate memory
- tune load factor
- lựa chọn hash function tốt
Fast lookup là một trong những vấn đề cơ bản nhưng cực kỳ quan trọng trong hệ thống backend. Việc sử dụng Hash Table (tự xây dựng hoặc thông qua các hệ thống như Redis, Memcached) giúp: lookup(key) -> O(1). Cho phép hệ thống xử lý hàng triệu request mỗi giây.
Hiểu rõ cơ chế hoạt động của Hash Table giúp chúng ta: hiểu cách cache systems hoạt động; thiết kế key-value storage hiệu quả, tối ưu performance cho các hệ thống backend lớn.